Before we dive in, please understand that this is an introductory level post and for the more technically inclined, there may not be much for consumption here. I will not go in depth on many topics surrounding search engines as a whole and may not fully elaborate on some dorking elements. Please feel free to reach out if you have more questions!
For most people, searching the internet or “Googling” something has become an intricate part of our lives. Anytime we want to know something we can just pull out our phone, sit at our computer, and even for many just talk to the smart devices in your house to get search results from Google or other search engines. However, few people understand or realize the power of the search engines we use today so I hope to examine ways we can get more refined results and even identify things search engines have indexed (put in their results) that the owners of that content never intended to be shared.
WHAT IS A SEARCH ENGINE?
Search engines are essentially servers that crawl the internet and save the locations of what they see in a database and then allow you to search them. Crawlers are scripts that reach out to web servers and navigate all the pages and links they can find to build a comprehensive picture of what is on the site and make it searchable. They do this through a variety of ways which I won’t go into now, but a common way is through a site map. Many pages include a site map which is an index of every sub-page on their site. This makes it very easy for a crawler or visitor to view the file and see everything they want you to know exists on their website. You can see an example of this from Chase Bank here.
Different search engines have different ways of crawling the internet and indexing their data for searching. This is why your results will not always be the same on sites like Google, Bing, and Yahoo.
ADVANCED SEARCH SYNTAX AND DORKING
Most search engines have documented advanced search parameters you can use to return more refined results. Though most of the things you typically search won’t require these, for the researcher who is looking for more obscure information this can be incredibly helpful.
The term that’s widely used for stringing these advanced search parameters together is often called “dorking”. Where did the term come from? Well, I couldn’t tell you. However, if you’re going to be getting more involved with these kinds of searches, this is definitely a term you want to be familiar with. Might as well just burn it into your brain right now that dorking is basically “fancy searching”. You may also hear the term “Google Hacking” as well for conducting searches in this way. Both are often interchangeable. In fact the larger research community has even begun collecting pre-written Google dorks for others to use for various needs here.
A larger and more comprehensive list of these search options can be found here, however I will include some of my most common used ones for Google below:
| Query | What is it? | Example |
|---|---|---|
| - | This allows you to filter results you don't want. | To search pages containing the word bank but explicitly excluding pages mentioning Chase you can use: "bank" -Chase |
| site: | This allows you to search pages within a specific site. | To search Apple for pages mentioning iPod you could use: site:apple.com "iPod" |
| inurl: | Similar to site, inurl allows you to search all indexed URLs for a keyword. | To search for login pages you might try: inurl:login |
| intitle: | This searches the title of the page, the title is the text that appears in the "tab" of your web browser telling you what it is. | To find pages hosting files, you may want to try: intitle:"Index of /" |
| intext: | Everything else so far has been related to the selectors that identify the site. Intext goes within the content of the site to search text within the page. | To identify pages explicitly mentioning your name, you might try: intext:"My Name" |
| filetype: | A favorite among many, filetype lets you search for files within webservers that are shared (intentionally or unintentionally) and indexed by the search engine. | Perhaps you want to just pull up a list of list of txt files. You can run: filetype:txt |
PUTTING IT TO USE AND CHAINING SYNTAX
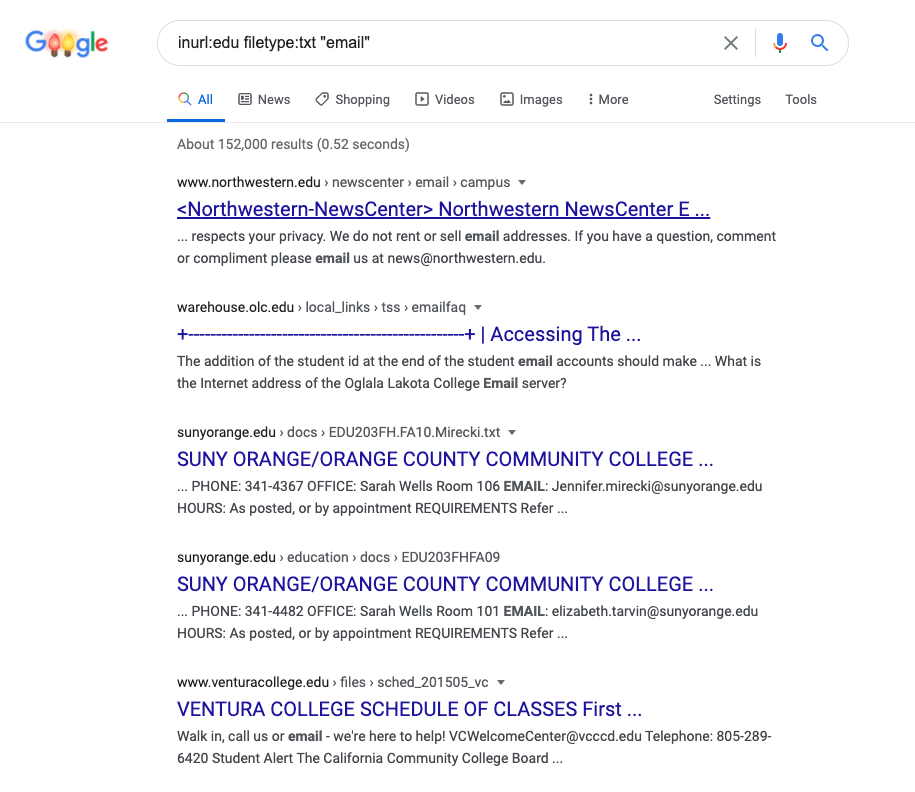
None of these search syntax functions are required to be used by themselves. They can be, but they become very powerful and more precise when chained together. Let’s take for example this query: inurl:edu filetype:txt "email". This says search for the keyword “email” and display “txt” files for sites with “edu” in the title which are typically sites related to schools.
FINAL THOUGHTS
I hope you have found this helpful. If you find anything that is in error, please reach out and let me know. If you’re interested in, or need help in forming more refined queries, please let me know at my name (at the top of this post) at this domain. Until next time!